Summary:
This is a real-life case study about one of my work projects. Facing inefficiencies and limitations of the no-code tool we used, I built a Chrome extension to streamline our data analysis process and enhance error detection.
This tool reduces the time we spend on manual data checks and analysis by 25% per month, significantly boosting team productivity.
Tools, I leaned on: JS, Python, GCP.
Working in a small non-profit in a fast-paced environment usually puts you in a place where you need to choose between using an overpriced technical tool or a cheap tool. Choosing cheap doesn’t always mean that it suits your needs, but it always means that you need to do an additional job to make it work for you.
In my job as a Technical and Data Director in the Localyst, I met this problem face to face. The main tool used in the company daily and made up 90% of the work was a no-code platform for assembling automatic bots for Facebook Messenger. Since the team had no developers and was a venture of a non-profit incubator that used the same platform, this was a logical decision. Before I was hired on the team, data analysis from the Facebook bot was done manually through this no-code platform. In one of the tabs, there was a database of users, and when building the bot, special attributes were assigned to each user who performed a certain action (clicked on a button and received an attribute).
Since the company was engaged in a narrative change about renewable energy, the bot was the main place for distributing content, and collecting and analyzing data was crucial in making decisions about the company’s further actions.
Unfortunately, life is more cunning than our plans, and while I was writing the same scripts in Python weekly, the platform we were using began to increase the number of errors rapidly. The main one was the lack of validation of the attribute field assigned to the user. Thus, one day we were unable to receive data on clicks in the broadcast we sent because the attribute contained a hidden symbol - line break. Of course, when checking the bot, this symbol was not visible and only after researching this error, I managed to find what was wrong by digging into the Chrome dev tool and the requests that were sent from the platform’s front end to their database.
It is necessary to flag, that we made an attempt to contact support with this bug but, unfortunately, we were told that this was not a bug on their side, but our mistake, and I must prohibit the team from copy-pasting so this mistake won’t repeat.
Copy-paste ban in 2023 lol
Due to this and other imperfections of the platform (for example, the lack of an API for pulling a database from the platform), I decided that I needed to build an extension for Chrome. Firstly, it had to automate routine daily work with scripts, and secondly, the platform’s interface had to be modified so that not only I can catch the errors, poking around in the Chrome dev tool, but also any member of the team who builds bot could do it simply. Since I was the one developer on the team, I needed to make this extension with minimal effort, since there was no time for thoughtful development and I had to continue to deliver the whole scope of my usual tasks.
I divided the task into 2 stages:
- Attribute verification. Insert a button into the interface and by clicking on it the attributes will be checked
- Automation of Analysis. Insert a button into the interface and by clicking on it the bot will be automatically analyzed and return to me CSV with this analysis.
Little did I know, that at every stage new adventures await me.
However, the impact of this extension was significant. It reduced the time spent on manual data analysis by 25% per month, increasing our team’s productivity and data accuracy.
This project was not just about technical execution; it was a journey of constant learning and adaptation. I navigated through unexpected challenges, from deciphering a complex GraphQL database to addressing cross-origin resource sharing (CORS) issues, each obstacle providing valuable insights into the intricacies of extension development and data handling.
But let’s dive deeper into each stage!
Stage 1: Attribute verification
Previously, in order to check each attribute of the bot, you needed to click on an average of 6-7 pages and check the block with the attribute on each one. In this case, an error in an attribute can be either in its name or in its value.
Since I already knew where the attribute name and value are stored in the Chrome dev tool, and I needed to collect all the attributes for a specific block group (block group = 1 bot), I decided to try to pull them all using the API.
Unfortunately, such request was not written by the platform developers and I had to write it myself. The platform used a GraphQL database and it is necessary to say, that there are GraphQL databases that are well-written and take the common sense into account, but this was not our case.

After spending a couple of days learning how to write a request to the platform database, which began to be written when the company was a small service, but then they kept adding the new data in a random order, instead of rewriting it in a normal form, I managed to pull out all the bot attributes.
After that, I started the front end part - added a button next to each group of blocks in the interface and wrapped everything in an extension.
By clicking on the button, we send a request to the platform server with the block group id and receive a CSV table with the columns “block name”, “attribute name”, and “attribute value”. If there is a hidden character in the name or value of an attribute, you can easily notice this in the table, go to the desired block and correct the attribute. For all my colleagues to be able to use the extension, I take their User ID from the Chrome dev tool when they first launch the extension.
Stage 2. Automation of analysis
Before I completed the first stage of my Chrome extension, bot analysis was the same Python script with classes and functions, to which I passed different attributes based on the bot that we sent to subscribers. This routine and unpleasant work took time, and besides, thanks to Stage 1 of the extension, I already had a ready CSV table with attributes, so it seemed to me that adding this feature should be easy.

To carry out data analysis, previously I needed to manually download the database from the platform since the platform did not have an API for these purposes. So you can imagine how much time you’ll spend if you have a database of 200K+ users, and you need to wait for a request to an overcomplicated GraphQL database to save this database (an assumption that in 2023 no one needs the data backups should be illegal).
But to automate the analysis, I need to have a fresh database daily, and this database should be in the company’s storage and it should get there automatically.
To solve this problem, I used the good old Chome dev tools and reverse engineering to write the request that would work. Then, I put this request into the Google Function, so it receives the latest database and sends it to our Google Cloud Storage. Also, I added a Google Scheduler, that triggers the Function every day at 7 am.
When I thought about the architecture of this stage, I didn’t know that the main issue would wait for me at the end.
On the front end side, I put a second button (next to the attribute collection button), by clicking on it the attributes are collected and sent to the script for analysis.
On the backend side, the Python script should receive attributes, take the latest database backup from the Storage, conduct an analysis, and send an additional request to the platform to take the number of broadcast recipients from another part of its database (yes, unfortunately, this number doesn’t live in the main database) and collect the resulting analysis in a table, that should be familiar to stakeholders and the team and return the table in CSV form to the front end.
I decided to deploy this Python script into Google Functions because it was familiar and convenient, plus it was a logical step to simplify working with our Cloud Storage. The adventure began when I realized that I could not send anything from the Google Extension to a function due to CORS restrictions.

I tried to Google and ChatGPT the issue and decided to use a background script, which operates and runs in a privileged context within the extension and is not subject to the same CORS restrictions as content scripts. To bridge the gap between the content script and the background script, I used chrome.runtime.sendMessage, which helps to secure communication between different parts of the extension, besides handling the HTTP requests and responses.
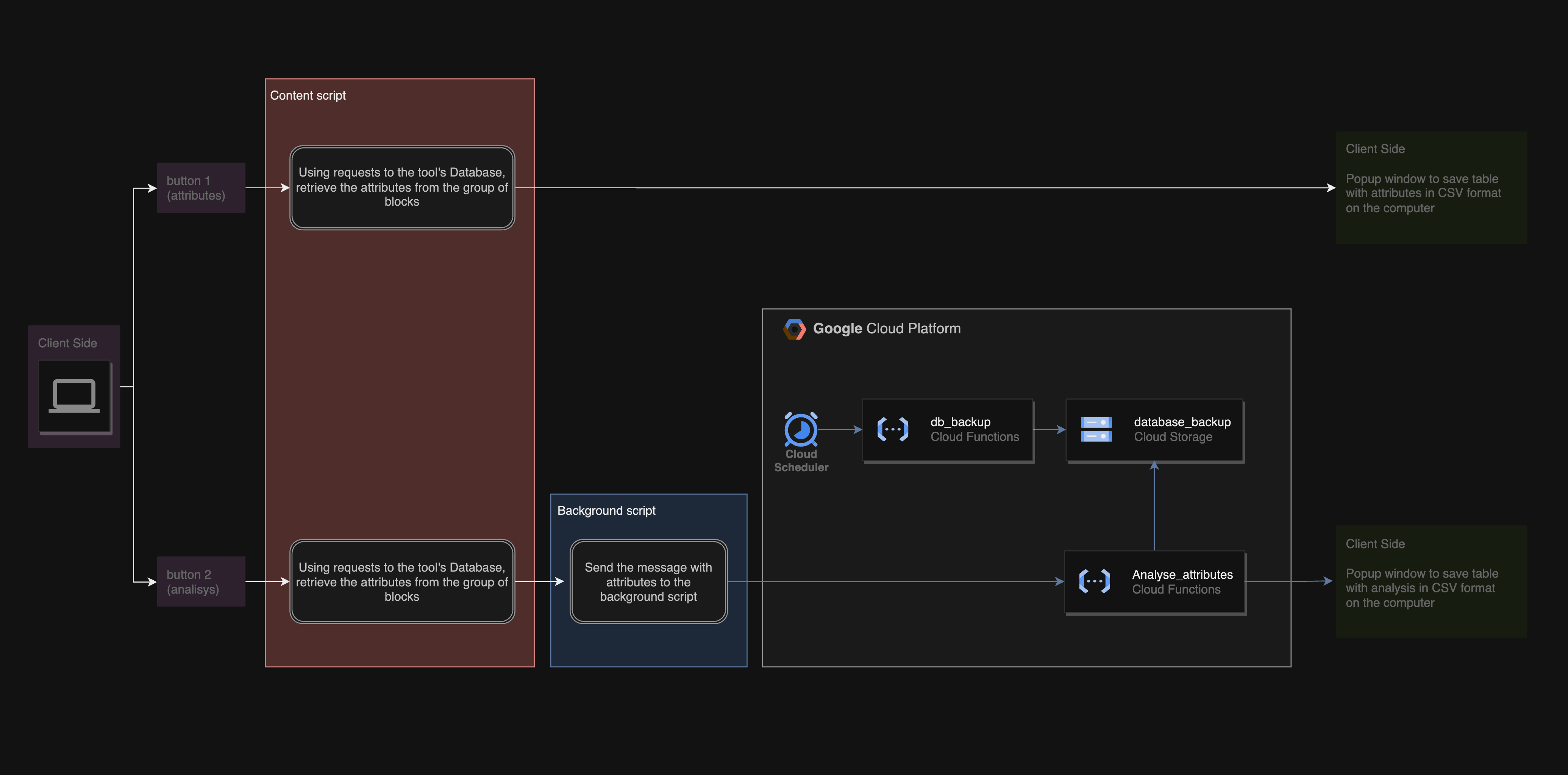
Final extension architecture
The main insight here is that even with a lot of cool tools for data analysis and pipelines, we still have to reinvent the wheel.
p.s. Currently, I am exploring ways to scale this solution. I already built Version 2, adding the integration of real-time data syncing with our Looker Dashboard, further streamlining our workflow. This experience has been pivotal in my professional growth and I’m eager to apply all the skills and insights from it in future challenges.